Over the past year, we’ve supported a couple dozen hackathons across Canada and beyond. From UofT Hacks and McHacks to KingHacks, SF Hacks, Waterloo events, and AI Collective Paris, we’ve seen the same pattern again and again:
When hackers get real AI infra on day one, they build way more than they thought possible by day three.
This post is for hackathon organizers who want their participants to ship ambitious AI projects without spending half the weekend debugging infrastructure.
What We Bring to Hackathons
Our goal at every event is simple:
Make it possible for teams to build stateful, multi-agent, RAG-powered apps in a weekend.
We’ve brought this to:
UofT Hacks
McHacks (McGill)
KingHacks
SF Hacks
AI Collective Paris
Waterloo hackathons (like CxC Waterloo and UW Listen)
…and many more university and community events
Our typical support has included:
Free Backboard credits for participants
Quickstart templates so teams start with working code
Workshops and office hours to get hackers unstuck fast
Judging and special prizes for best use of Backboard
Under the hood, the thing hackers actually feel is:
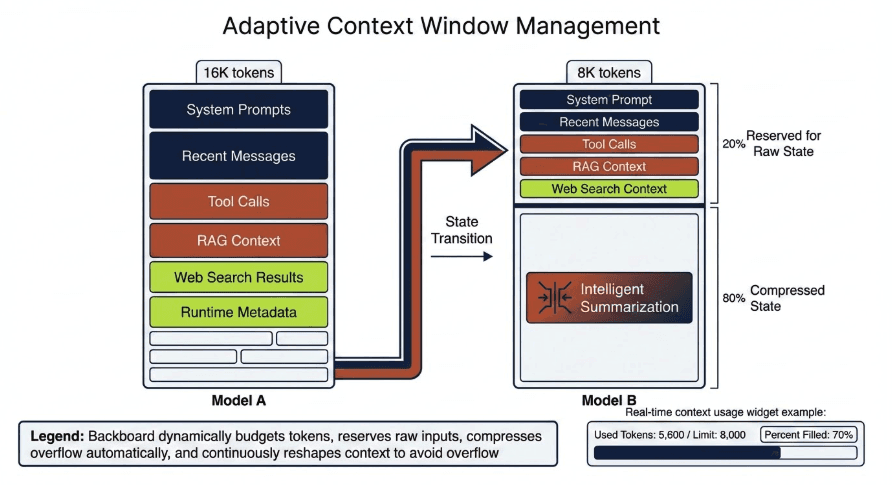
Backboard is a stateful AI platform: built‑in state, memory, and RAG so teams can ship multi-step, multi-agent apps fast.
Instead of wiring multiple providers, standing up custom vector stores, and bolting on “memory” at 3 a.m., teams call one API and focus on their idea.
How Participants Benefit
The comments we hear from participants are remarkably consistent:
“We had our entire infra up and running in minutes.”
“We were able to build way more than we thought!”
“I wouldn’t have pulled this off without Backboard.”
In a 24–48 hour sprint, that matters.
Infra in Minutes, Not Hours
With Backboard, teams can:
Spin up stateful conversations with built-in memory
Plug in RAG over their own docs and data
Orchestrate multi-step, multi-agent flows from a single API
That means less time fighting setup, and more time on UX, features, and polish.
From “Simple Bot” to Multi-Agent Swarms
At events like UofT Hacks, McHacks, and Waterloo hackathons, we’ve seen the same journey:
Teams show up planning to build a basic chatbot.
A few hours in, they realize they can build multi-agent swarms where:
Each agent has its own LLM and role,
All agents share a persistent memory,
The system improves iteratively over the weekend.
In one project, a team used Backboard’s shared memory to train and refine agents over the course of the hackathon. That kind of system is non-trivial to wire from scratch. With Backboard, they just pointed their agents at the same memory and iterated on behavior instead of infrastructure.
Those are the projects that tend to land on the podium.
How Organizers Benefit
For organizers, the value is direct:
When builders can ship more, your hackathon looks better.
Better, More Polished AI Projects
Because teams start with production-grade AI infra, final demos are:
More robust (fewer “it worked on my laptop at 5 a.m.” moments)
More feature-complete (real flows, real RAG, real state)
Easier to showcase in recap posts and highlight reels
Your hackathon becomes known as the place where serious AI projects get started, not just toy demos.
Happier, More Empowered Builders
Participants tell us they:
Got farther than they expected in the time they had
Built something they’re excited to keep hacking on
Became genuine Backboard superfans—and remember the event that introduced them to it
Organizers see the knock-on effects: better feedback, stronger community, and more repeat participation.
A Partner That Actually Shows Up
We don’t just drop credits and a logo.
At many events, we’ve:
Run live workshops on building stateful, multi-agent, and RAG-powered apps
Hosted office hours during crunch time
Judged final projects and sponsored “Best Use of Backboard” prizes
Shared standout projects and events across our channels
We can also share high-level usage insights (how many teams built on Backboard, what they built) and extend credits for teams that want to keep going post-hackathon.
The end result: your community gets more out of the weekend, and your event brand gets stronger.
Why Backboard Is a Great Fit for AI-Heavy Hackathons
If you’re running an AI-focused event—or you know most teams will be using LLMs—just handing out API keys isn’t enough anymore.
Backboard gives your hackers:
The Stateful AI Platform
Built-in state and memory, so they can build multi-step workflows, persistent assistants, and multi-agent systems without standing up their own infra.
RAG Out of the Box
Let teams attach their own docs and data and build genuinely “smart” apps in a weekend.
A Unified Surface for Ambitious Ideas
One place to experiment with agents, tools, memory, and retrieval—and still have a demo-ready project by closing ceremony.
That combination is why Backboard keeps showing up in winning and finalist projects at the hackathons we support.
Want Backboard at Your Next Hackathon?
If you’re organizing a university or community hackathon and want your builders to ship more advanced AI projects in less time, we’d love to talk.
We offer:
Free credits for your participants
Hackathon-ready templates and quickstarts
Optional workshops, office hours, and judging for select events
Extra visibility for standout projects and events via our networks
You can:
Email us directly at: hackathon at backboard.io
Tell us a bit about your event and dates, and we’ll see how we can give your builders the stateful AI platform they deserve.