

Announcement
Backboard Achieves Highest Score Ever on LoCoMo (90.1%)
New stateful memory architecture. Standard protocol. Fully reproducible.
A funny thing happened on the way to baseline our novel AI Memory architecture by using the industry standard benchmark, LoCoMo: We broke the record. And we did it with no gaming, no adjustments, just pure, reproducible execution!
Backboard scored 90.1 percent overall accuracy using the standard task set and GPT-4.1 as the LLM judge. Full results, category breakdowns, and latency are available below, along with a one-click script and API so anyone can replicate the run. This is now LIVE in our API so anyone can plug in and start testing.
Full Result set with replication scripts here: https://github.com/Backboard-io/Backboard-Locomo-Benchmark
About the Benchmark
LoCoMo was designed to test memory across many sessions, long dialogues, and time-dependent questions. It is widely used to evaluate whether systems truly remember and reason over long horizons. snap-research.github.io+2arxiv.org+2
How we compare
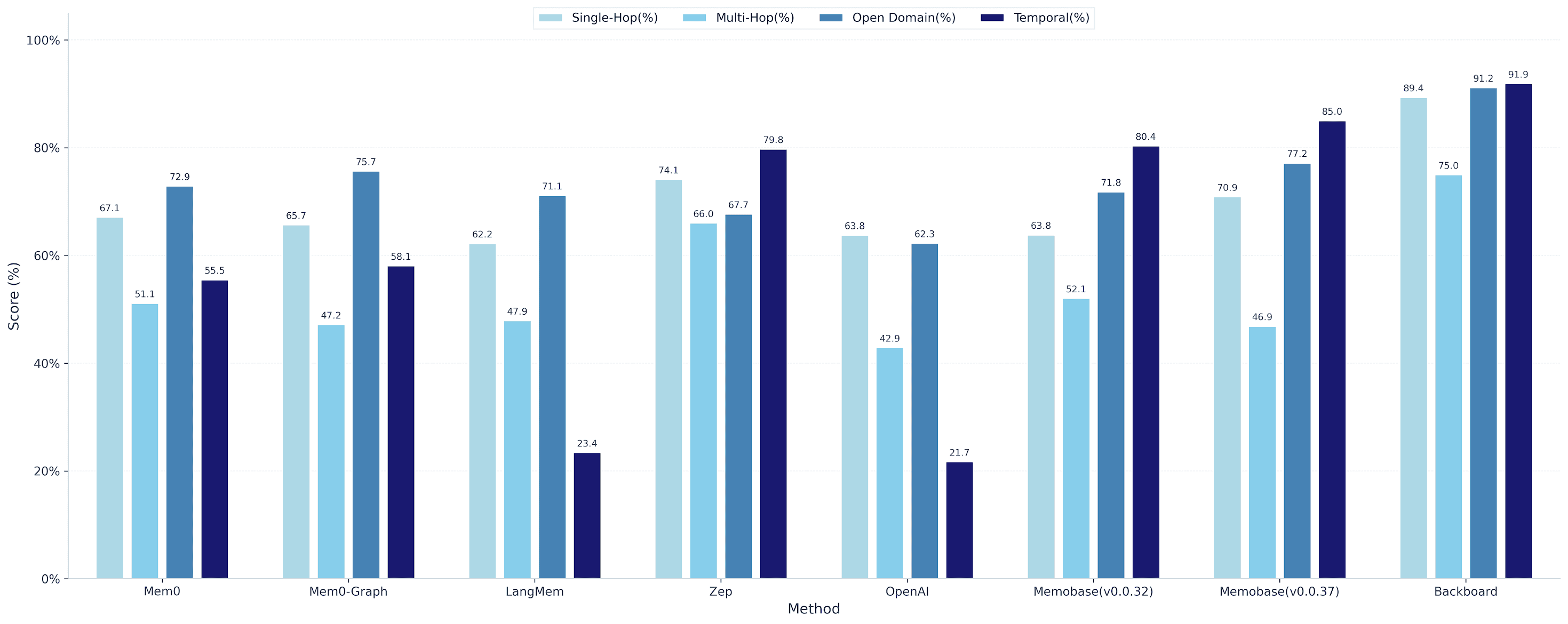
Recent public writeups place leading memory libraries around 67 to 69 percent on LoCoMo, and a simple Letta filesystem baseline around 74 percent. Backboard’s 90.1 percent suggests a material step forward for long-term conversational memory. We will maintain a live comparison table on our results page.
Method | Single-Hop(%) | Multi-Hop(%) | Open Domain(%) | Temporal(%) | Overall(%) |
Backboard | 89.36 | 75 | 91.2 | 91.9 | 90 |
Mem0 | 67.13 | 51.15 | 72.93 | 55.51 | 66.88 |
Mem0-Graph | 65.71 | 47.19 | 75.71 | 58.13 | 68.44 |
LangMem | 62.23 | 47.92 | 71.12 | 23.43 | 58.1 |
Zep | 74.11 | 66.04 | 67.71 | 79.79 | 75.14 |
OpenAI | 63.79 | 42.92 | 62.29 | 21.71 | 52.9 |
Memobase(v0.0.32) | 63.83 | 52.08 | 71.82 | 80.37 | 70.91 |
Memobase(v0.0.37) | 70.92 | 46.88 | 77.17 | 85.05 | 75.78 |
Best in Class in Every Measure
Reproducibility and transparency
Same dataset and task set as LoCoMo
GPT-4.1 LLM judge with fixed prompts and seed
Logs, prompts, and verdicts published for every question
Run it yourself in minutes using our public script or by calling the evaluation API.
If memory is the foundation of intelligence, transparency must be the foundation of benchmarks.
Get started
Build with Backboard today. Sign up takes under a minute.
References
LoCoMo benchmark overview and paper. snap-research.github.io+2arxiv.org+2
Changelog